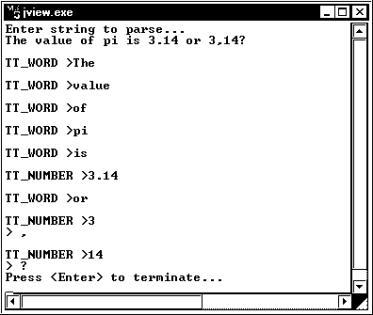
Microsoft Visual J++. —оздание приложений и аплетов на €зыке Java. „асть 2© јлександр ‘ролов, √ригорий ‘ролов“ом 32, ћ.: ƒиалог-ћ»‘», 1997, 288 стр. ѕриложение StreamToken¬ приложении StreamToken мы демонстрируем использование класса StreamTokenizer дл€ разбора входного потока. ¬начале приложение запрашивает у пользовател€ строку дл€ разбора, записыва€ ее в файл. «атем этот файл открываетс€ дл€ чтени€ буферизованным потоком и разбираетс€ на составные элементы. аждый такой элемент выводитс€ в отдельной строке, как это показано на рис. 2.6.
–ис. 2.6. –азбор входного потока в приложении StreamToken ќбратите внимание, что в процессе разбора значение 3.14 было восприн€то как числовое, а 3,14 - нет. Ёто потому, что при настройке разборщика мы указали, что символ С.Т €вл€етс€ обычным. »сходный текст приложени€»сходный текст приложени€ StreamToken представлен в листинге 2.5. Ћистинг 2.5. ‘айл StreamToken\StreamToken.java
// =========================================================
// –азбор входного потока при помощи класса
// StreamTokenizer
//
// (C) ‘ролов ј.¬, 1997
//
// E-mail: frolov@glas.apc.org
// WWW: http://www.glasnet.ru/~frolov
// или
// http://www.dials.ccas.ru/frolov
// =========================================================
import java.io.*;
// =========================================================
// ласс StreamToken
// √лавный класс приложени€
// =========================================================
public class StreamToken
{
// -------------------------------------------------------
// main
// ћетод, получающий управление при запуске приложени€
// -------------------------------------------------------
public static void main(String args[])
{
// ¬ыходной поток
DataOutputStream OutStream;
// ¬ходной поток
DataInputStream InStream;
// ћассив дл€ ввода строки с клавиатуры
byte bKbdInput[] = new byte[256];
// ¬веденна€ строка, котора€ будет записана в поток
String sOut;
try
{
// ¬ыводим строку приглашени€
System.out.println("Enter string to parse...");
// „итаем с клавиатуры строку дл€ записи в файл
System.in.read(bKbdInput);
// ѕреобразуем введенные символы в строку типа String
sOut = new String(bKbdInput, 0);
// —оздаем выходной буферизованный поток данных
OutStream = new DataOutputStream(
new BufferedOutputStream(
new FileOutputStream("output.txt")));
// «аписываем строку sOut в выходной поток
OutStream.writeBytes(sOut);
// «акрываем выходной поток
OutStream.close();
// —оздаем входной буферизованный поток данных
InStream = new DataInputStream(
new BufferedInputStream(
new FileInputStream("output.txt")));
// —оздаем объект дл€ разбора потока
TokenizerOfStream tos = new TokenizerOfStream();
// ¬ыполн€ем разбор
tos.TokenizeIt(InStream);
// «акрываем входной поток
InStream.close();
System.out.println("Press <Enter> to terminate...");
System.in.read(bKbdInput);
}
catch(Exception ioe)
{
System.out.println(ioe.toString());
}
}
}
// =========================================================
// ласс TokenizerOfStream
// ласс дл€ разбора входного потока
// =========================================================
class TokenizerOfStream
{
public void TokenizeIt(InputStream is)
{
// —оздаем разборщик потока
StreamTokenizer stok;
// ¬ременна€ строка
String str;
try
{
// —оздаем разборщик потока
stok = new StreamTokenizer(is);
// «адаем режим исключени€ комментариев,
// записанных в стиле —++ (два символа '/')
stok.slashSlashComments(true);
// ”казываем , что символ '.' будет обычным символом
stok.ordinaryChar('.');
// «апускаем цикл разбора потока,
// который будет завершен при достижении
// конца потока
while(stok.nextToken() != StreamTokenizer.TT_EOF)
{
// ќпредел€ем тип выделенного элемента
switch(stok.ttype)
{
// ≈сли это слово, записываем его во
// временную строку
case StreamTokenizer.TT_WORD:
{
str = new String("\nTT_WORD >" + stok.sval);
break;
}
// ≈сли это число, преобразуем его
// в строку
case StreamTokenizer.TT_NUMBER:
{
str = "\nTT_NUMBER >" +
Double.toString(stok.nval);
break;
}
// ≈сли найден конец строки,
// выводим строку End of line
case StreamTokenizer.TT_EOL:
{
str = new String("> End of line");
break;
}
// ¬ыводим прочие символы
default:
{
if((char)stok.ttype == '"')
{
str = new String("\nTT_WORD >" + stok.sval);
}
else
str = "> " +
String.valueOf((char)stok.ttype);
}
// ¬ыводим на консоль содержимое временной строки
System.out.println(str);
}
}
catch(Exception ioe)
{
System.out.println(ioe.toString());
}
}
}
ќписание исходного текста приложени€ѕосле ввода строки с клавиатуры и записи ее в файл через поток наше приложение создает входной буферизованный поток, как это показано ниже:
InStream = new DataInputStream(
new BufferedInputStream(
new FileInputStream("output.txt")));
ƒалее дл€ этого потока создаетс€ разборщик, который оформлен в отдельном классе TokenizerOfStream, определенном в нашем приложении: TokenizerOfStream tos = new TokenizerOfStream(); ¬след за этим мы вызываем метод TokenizeIt, определенный в классе TokenizerOfStream, передава€ ему в качестве параметра ссылку на входной поток: tos.TokenizeIt(InStream); ћетод TokenizeIt выполн€ет разбор входного потока, отобража€ результаты разбора на консоли. ѕосле выполнени€ разбора входной поток закрываетс€ методом close: InStream.close(); —амое интересное в нашем приложении св€зано, очевидно, с классом TokenizerOfStream, поэтому перейдем к его описанию. ¬ этом классе определен только один метод TokenizeIt:
public void TokenizeIt(InputStream is)
{
. . .
}
ѕолуча€ в качестве параметра ссылку на входной поток, он прежде всего создает дл€ него разборщик класса StreamTokenizer: StreamTokenizer stok; stok = new StreamTokenizer(is); Ќастройка параметров разборщика очень проста и сводитс€ к вызовам всего двух методов:
stok.slashSlashComments(true);
stok.ordinaryChar('.');
ћетод slashSlashComments включает режим распознавани€ комментариев в стиле €зыка программировани€ —++, а метод ordinaryChar объ€вл€ет символ С.Т обычным символом. ѕосле настройки запускаетс€ цикл разбора входного потока, причем условием завершени€ цикла €вл€етс€ достижение конца этого потока:
while(stok.nextToken() != StreamTokenizer.TT_EOF)
{
. . .
}
¬ цикле анализируетс€ содержимое пол€ ttype, которое зависит от типа элемента, обнаруженного во входном потоке:
switch(stok.ttype)
{
case StreamTokenizer.TT_WORD:
{
str = new String("\nTT_WORD >" + stok.sval);
break;
}
case StreamTokenizer.TT_NUMBER:
{
str = "\nTT_NUMBER >" + Double.toString(stok.nval);
break;
}
case StreamTokenizer.TT_EOL:
{
str = new String("> End of line");
break;
}
default:
{
if((char)stok.ttype == '"')
str = new String("\nTT_WORD >" + stok.sval);
else
str = "> " + String.valueOf((char)stok.ttype);
}
}
Ќа слова и численные значени€ мы реагируем очень просто - записываем их текстовое представление в рабочую переменную str типа String. ѕри обнаружении конца строки в эту переменную записываетс€ строка End of line. ≈сли же обнаружен обычный символ, мы сравниваем его с символом кавычки. ѕри совпадении в переменную str записываетс€ содержимое пол€ sval, в котором наход€тс€ слова, обнаруженные внутри кавычек. ≈сли же обнаруженный символ не €вл€етс€ символом кавычки, он преобразуетс€ в строку и записываетс€ в переменную str. ¬ заключении метод выводит строку str в стандартный поток вывода, отобража€ на консоли выделенный элемент потока: System.out.println(str); |
Ѕиблиотека
Ѕратьев
‘роловых
Ѕратьев
‘роловых